hi,好久不见!有近半年未更新了。我先自罚三杯吧。
一杯是为了农田里犁头与泥土的约定,一杯是为了地铁里被挤压的青春。最后一杯,为了莫名者散落于代码间的悲喜。
今天要讨论的话题是,结构体 (Struct)。摸着良心讲,结构体真的很简单!但作为一个旨在入门的系列教程,没有理由把它绕过去。个人觉得,越是简单的东西,越是不好写。在写这篇文章之前,我几经徘徊,无从下手。到目前为止,此文可能是最差的那一篇吧。发布出来,权当抛砖引玉吧!
我们知道,内存里存放的是无差别的 0 与 1 的序列。“天地不仁,以万物为刍狗”。这是一片混沌的世界,在内存的眼里,众生平等,无界无相无色,无贵贱亦无高下。为了给这个混沌的世界带来光,Rust 提供了基本数据类型(比如整型、字符等),这样就可以对 0 与 1 的序列进行有意义的解读。至此,混沌的世界有了生气。但仅仅依靠这些基本数据类型,不足以 (或者说不方便) 构建绚丽多彩的世界。于是,Rust 又提供了另一个神器,让我们能够自定义各种数据类型以建模业务世界。这个神器,就是自定义类型,在 Rust 中包括结构体(Struct)、枚举(Enum)、联合体(Union)。当然,本文只说结构体,嗯。
可以通过结构体来自定义要想的数据类型,它刻画了这个类型应当由哪些部分组成、各个部分对应的名字与类型以及作为结构体整体上所应支持的行为,然后,它将作为一个整体被 CPU 所理解与使用。如果把基本数据类型比作是建构房屋的砂石、水泥、钢筋、砖块等单元材料,那么结构体就是由这些单元定制的各种预制构件。
好了,故事讲得差不多了。现在让我们来看看在 Rust 中结构体 (Struct) 的具体情况吧。
在 Rust 中结构体的定义语法如下:
struct StructName { //名称以大小字母开头,采取驼峰式拼写
field1: data_type1,
field2: data_type2,
field3: data_type3,
...
}
结构体定义以struct关键字开头,后面紧跟着结构体的名字(名字的首字母通常大写),然后在名字后跟上一对花括号({通常不换行)。在花括号内,列出你希望结构体所包含的内容,这些内容是由一条条称为字段的东西组成的。比如 field1: data_type1,,这就是一条字段,它定义了一个叫做field1字段,它所对应的类型是data_type1。各个字段之间用,分隔,作为一种习惯,即使是最后一个字段的后面也会默认带上,,这么做的好处也是显然的,比如要在一个已有结构体中插入或者新增一个字段时至少可以少按一次键盘😁。一个字段的类型可以是基本类型,也可以其他已经定义好的结构体类型,还可以是指向正在定义的本结构体的指针类型。
嗯,这就是结构体定义的全部内容了,是不是很简单呢?现在来看一个具体的例子吧。
在具体写代码之前,我想交代一下背景,这可能会贯穿到我们后续的一系列文章中。我们正在用 Rust 写一部中国农耕文化史,记录我们记忆深处的故事。
话说大明洪武年间,在湖广省辰州府有一座圣人山,顶上有一冬瓜岭,这里居住一个叫刘一明的人,时年三十又三。说起刘一明,有一段来历。一明本系江西吉安府人,两年前迁于此。公子聪慧过人,自幼读圣贤,十六即中秀才。然因时运不济,屡试不第,至而立仍为布衣,且孑然一身。某夜梦一赤眉仙人,身披丹甲,脚踏祥云,头生两角如钳,不知何方神圣。仙人劝戒一明远离功名,并赐诗一首与他,诗云:金陵三月好风光,秦淮烟柳转眼空。焚书西行遇圣人,枕瓜而眠粮万顷。梦醒,一明顿悟,其心犹云破月来。遂焚书十担余,誓忘功名。是年洪武廿六年,岁次癸酉,适逢“洪武移民”,一明随众一路西行。逾月余,至一千又二百余里处,忽遇一山。巍巍然齐天,白云束腰,望之或有仙气。问之何山?答曰:圣人山。又指白云生处,复问之何地?答曰:冬瓜岭也。一明甚喜,岂非“枕瓜而眠”乎?遂伐木结庐、累石起灶定居于岭上,拓荒开路、播谷栽菽,已二载余也。
这是一段从书本到农田的弃文从农之路。辛酸无奈,但又洒脱从容,还有希望与欢愉。是的,农田一直是勇者乐园,乡村始终是本真的起点。我们的文化,就在那泥土的一翻一覆间;我们的情怀,就在那锄犁的声声碰撞中。寺庙与朝堂,只是懦夫、窃盗者与流氓们的临时庇护所。
对不起,我知道已经跑题了,让我们立马回归正题。刘先生为方便出行与驮运农货,花了 12 两白银,托人从二百里余外的宝庆府马贩张老六处买了一匹白马。现在让我们为其设计一个数据类型。稍加思考,其代码可能如下:
struct Horse { //给这个新的类型取了一个名字:Horse
name: String, //马的名字,假设马的数量不会太多,主人用不同名字就可以区别
age: u8, //马的年龄,以月计算
gender: u8, // 马的性别,规定1是公马、0是母马
skin_color: String, //马的肤色,比如白马、黑马、枣红色、或者是杂色等
}
很简单,是吧。现在,一个全新的数据类型 Horse 就定义好了。
那应该怎么去使用这个类型呢?如何用马这个类型,去创建或者说记录一个实实在在的马呢?这就是结构体实例化问题。
在 Rust 中实例化结构体的完整语法如下:
SomeStructName {
field1: field1_value,
field2: field2_value,
field3: field3_value,
...
}
我们要实例化(记录)老刘买的小白马,其代码如下:
let white_horse = Horse {
name: "丰行".to_string(), //"丰行",寓意着五谷丰登
age: 26,
gender: 1, // 1 表示是公马
skin_color: "白色".to_string(),
};
可以通过.运算符,从结构体实例中获取某个字段的信息。比如想知道上面这匹马的年纪:
let age = white_horse.age;
如果要修改结构体实例中的某个字段信息,可以直接对字段进行赋值。比如要更改马的年纪:
white_horse.age = 27;
由于结构体中各个字段是以结构体作为一个整体被使用的,修改某个字段信息,等同于修改了这个结构体实例。所以要使一个结构体实例能被修改,必须要符合我们之前所说的有关变量可变性的规定,也就是说,在定义white_horse变量时必须加上mut关键字,即let mut white_horse = ...
在一个函数或是方法中实例化一个结构体,如果字段的名称与其对应的欲赋值参数或者上下文中的变量名称相同,则可以省略字段名,直接写上参数或变量即可。例如:
// 参数与字段同名
fn build_horse(name: String, age: u8) -> Horse {
Horse {
name,//欲赋值变量与字段同名,都是name,省略字段名
age,//欲赋值变量与字段同名,都是age,省略字段名
gender:1,
skin_color: "白色".to_string(),
}
}
// 上下文中的变量与字段同名
let age = 28_u8;
let name = "丰行".to_string();
let gender = 1_u8;
let horse2 = Horse{
name,
age,
gender,
skin_color: "白色".to_string(),
};
当然,也可以通过一个已有的实例,来实例化一个新的结构体实例。刘一明同志,闻鸡而出、披星而归,加上精打细算,两年后手上又有了一大笔积蓄。为扩大生产,又找张老六购得一匹新马。此马与之前的白马同年同月同日生,也是公马。因其浑身枣红,老刘给它取名“赤瑶”,寓意红红火火、事业爱情双丰收。
现在,请我们为老刘记录一下这匹新买的马。代码可能如下:
let red_horse = Horse {
name: "赤瑶".to_string(),
skin_color: "枣红".to_string(),
..white_horse //注意:后面不需要加`,`
};
以上的代码创建了一个新马 red_horse,该实例只是名字与颜色不同于白马,其他的信息是一样的(age、 gender 字段的值与 white_horse 相同)。 ..white_horse 必须放在最后,以指定其余的字段应从 white_horse 的相应字段中获取其值,但我们可以选择以任何顺序为任意字段指定值,而不用考虑结构体定义中字段的顺序。
...white_horse,事实是只是一个语法糖。它表示对于欲实例化实例中未显式列出的字段,其值将用white_horse中对应的字段进行赋值。上面代码在背后的所对应的实际代码大概如下:
let red_horse = Horse {
name: "赤瑶".to_string(),
skin_color: "枣红".to_string(),
//..white_horse 等价下面的代码
age: white_horse.age,
gender: white_horse.gender
};
这里有一个问题需要注意,由于...white_horse是把一个实例中的字段值赋值另一个实例的字段,本质上是赋值行为,那么当然要遵循 Rust 中有关所有权的规定。换句话说,因字段类型的性质不同,当赋值时,要么发生复制行为,要么发生移动行为。如果是移动,意味着原变量将不可用,因为其相应字段信息被移走了(相当于这个结构体实例的这人字段,被人挖空了😜)。当然,我们上面的例子不会有问题,因为age与gender的类型为基本数据类型(均实现了Copy特征,关于特征后续会开专文讨论),在赋值时是复制行为,所以使用white_horse协助实例化red_horse后,white_horse仍然可用。
如果我们把代码修改一下,情况就不同了。比如下面的代码示例:
fn main() {
let mut white_horse = Horse {
name: "丰行".to_string(),
age: 26,
gender: 1,
skin_color: "白色".to_string(),
};
let red_horse = Horse {
name: "赤瑶".to_string(),
// 注释下面这一行,表示red_horse的颜色与white_horse 一样,赋值时发生移动行为
//skin_color: "枣红".to_string(),
..white_horse
};
println!("{:?}", white_horse);
}
上述代码,将无法通过编译,会提示类似value borrowed here after partial move的错误。白马的毛色信息赋值给红马的时候,其效果好比是把白马的毛全部拔光了,😂哈哈!当然,这不是我们今天的主题,只是在这里顺便复习一下之前的内容。
结构体,不光可以包含字段,还可以与函数相关联。结构体实例化后,在内存中表现为一连串的二进制序列。函数,通常被加载到内存中一个称为代码段地方,函数名称作为函数调度的单位,其事实上只是一个指针类型的实例,代表了对应函数代码序列的起始处地址。可见,在内存的角度看,两者是没有任何关系的。一个,面朝大海;一个,头顶青山。但为了表达一个结构体具备某种行为能力,即该类型或该类型的实例可以调用哪些函数,需要将两者关联起来。这样,这些函数在逻辑上就隶属于某个特定的结构体类型。这就是所谓的关联的实质,关联函数与关联方法在技术实现层面是一样的,只有概念与目的上的区别。
关联函数的语法如下:
impl SomeStructName {
fn func1_name(arg1: Arg1Type,arg2: Arg2Type,...) -> ReturnType {...}
fn func2_name(arg1: Arg1Type,arg2: Arg2Type,...) -> ReturnType {...}
fn func3_name(arg1: Arg1Type,arg2: Arg2Type,...) -> ReturnType {...}
...
}
要为一个结构体实现关联函数,使用impl关键字,在后面紧跟结构体名,然后用一对花括号开启一个代码区。在这对花括号中定义的函数,就是该类型的关系函数。函数定义的规则,与常规的函数定义没有什么区别。
现在,我们为马这个结构体来定义一个关联方法new:
impl Horse {
fn new(name: String, age: u8, gender: u8, skin_color: String) -> Self {
Horse {
name,age,gender,skin_color,
}
}
}
以上的代码中的new函数不是一个普通的函数,而是Horse的关联函数。该函数的功能是根据传入的参数,实例化一个 Horse 实例。这个函数有两点需要稍微解释一下,一是返回类型:Self,它是一种语法糖,等同于所关联的结构体的类型,在上例中就是Horse。另一个,就是函数内创建的实例的代码Horse{...}后面没有跟上;,它表示创建并返回,相当于 return Horse{...}; 。
使用关联函数的例子,比如下面代码,我们使用上面的定义的new函数。
let horse = Horse::new(
"丰行".to_string(),
28_u8,
1,
"白色".to_string()
);
在以上代码中,我们在调用new函数的前面加上了前缀Horse::,它表明new不是一个普通的函数,而是一个关联函数,其在逻辑上隶属于Horse类。所以,我们调用关联函数的时候,既要指明它所隶属的类型信息,还要指明函数本身的函数名信息。其中的::符号表示后者在前者的范围内。但在编译后的可执行文件中所包括的符号信息,可能会是类似:_some_prefix_horse_new_(...)形式的名称,可见关联函数本质还是一种普通函数,只是为表达既定的语义,编译作了额外的支持。
关联方法跟关联函数基本上是一样的,它们之间的区别仅仅在函数的参数上。这个区别,是由关联方法与关联函数在概念上的区别所导致的。关联函数,强调的是一个函数隶属于一个类型,相当于其他语言中的静态方法。而关联方法,则强调的是一个函数隶属于一个类型的实例,这一点与其他大部分的面向对象语言中的方法是一致的。
关联方法要求所定义的函数的参数中,有一个参数必须是self/&self/&mut self中的一种,这样,该方法就与实例之间存在一种关联了。其中self是self: Self的语法糖,表示调用方法的实例,其他两者分别表示调用方法的实例的不可变与可变引用。在impl SomeStruct代码区内定义的函数,如果满足上面对于参数的要求,那么它就是这个类型的关系方法,否则就是关联函数。
下面,举几个关联方法的例子吧。
impl Horse {
// 获取马儿的名字
fn get_name(&self) -> String {
let name = self.name.clone();
name
}
// 设置马儿的名字
fn set_name(&mut self, name: String) {
self.name = name;
}
fn run(self) {
// 马儿在奔跑...
}
fn carry(&self,goods: u16) {
// 马儿驮运货物
}
}
下面是具体使用这些关联方法的示例。
fn main() {
let mut horse = Horse::new(
"丰行".to_string(),
28_u8,
1,
"白色".to_string()
);
// 获取马儿的姓名
let name = horse.get_name();
//重新设置马儿的年龄
horse.set_name("赤瑶".to_string());
// 让马儿驮运 50kg 的货物
horse.carry(50);
// 让马儿奔跑起来,由于参数是self,运行该方法后,horse实例的所有权被移走
horse.run();
// 下面代码将无法通过编译,horse因调用run()而失效。
//_ = horse.get_name();
}
上面代码展示了如何用instance.method()方式调用一个关联方法,这种调用方式很符合人类的思维方式,感觉instance拥有了method这种行为,调用起来甚是自然。
事实上,instance.method()只是一种语法糖,编译器在背后会把它转换成:
SomeType::method(
instance/&instance/&mut instance,
other_rest_args...
);
比如,对于下面的代码:
horse.carry(50);
编译器会把它转换成:
Horse::carry(&horse,100);
编译器的这种转换,为程序员提供极大的便利,它会自动为instance 添加 &、&mut 或 * 以便使 instance 与方法签名匹配。比如,上面的代码中,horse是self类型,而carry要求的参数是&self,当直接用self类型的实例调用方法时,编译器自动用实例的引用(&self)传递到方法中。同理,如果参数要求是self,而调用者是&self,编译器会先把引用先解引用后*self),再把得到的本体传递到方法中。
对于一个结构体,可以使用impl为其开辟多个代码区,用于划分不同的的业务逻辑。在代码区内,既可以写关联函数,也可以写关联方法。
impl Horse {// 基本属性相关的代码区
...
}
impl Horse {// 出行相关的代码区
...
}
impl Horse {// 驮运农货相关的代码区
...
}
对于关联方法,最后一个需要提及的问题是,要注意在调用方法时的所有权转移问题。就是,如果一个类型没有实现Copy特征,当调用一个参数要求是self 的方法后,实例的所有权将发生转移。也这是,上面示例代码中,当调用horse.run()后,horse实例不可再用的原因。可见,所有权原则在 Rust 中无处不在!不熟悉的朋友,敬请查看我之前的相关文章。
元组结构体也是一种结构体,同样有自己的名字,只是没有具体的字段名,只有字段的类型。当你想给整个元组取一个名字,并使元组成为与其他元组不同的类型时,元组结构体是很有用的。
要定义元组结构体,以struct关键字和结构体名开头,后面紧跟着一个元组类型。下面是两个分别叫做 Color 和 Point 元组结构体的定义和用法:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}
注意 black 和 origin值的类型不同,因为它们是不同的元组结构体的实例。你定义的每一个结构体有其自己的类型,即使结构体中的字段有着相同的类型。例如,一个获取 Color 类型参数的函数不能接受 Point 作为参数,即便这两个类型都由三个 i32 值组成。在其他方面,元组结构体实例类似于元组:可以将其解构为单独的部分,也可以使用 . 后跟索引来访问单独的值。
单元结构体,没有包含有任何字段,仅仅只提供一个名字,它类似于空元组()类型。既然单元结构体不包含字段,那么设计这种类型的用意思是什么呢?如果你看了前面的内容,你应该知道结构体除了字段信息外,还有一个重要的信息就是关系函数或方法。对,设计这种类型之目的,就是为了给它增加关联函数或关联方法。当然也可以为它实现特征(Trait),我们后面会有专文讨论特征的话题。现在你只需要知道,所谓的特征在本质上也算是一种关联方法,只是在关联方法的基础上增加了一些限制罢了。
下在是一个单元结构体的例子。
struct UnitStruct;
impl UnitStruct {
fn do_something(&self) {}
}
fn main() {
let unit_object = UnitStruct;
unit_object.do_something();
}
可见,单元结构体除了没有字段外,与普通的结构体没有什么区别。
可见性是 Rust 中的重要内容,后续会开专文讨论。在这里,仅仅简单地说一下与结构体相关的内容。在讨论这个话题之前,我先声明一下:接下来的言辞,可能不精准,但不会影响对后续相关内容的理解。
所谓的可见性,是指一个类型能被访问的范围。对于结构体来说,主要有两层含义。一是,该结构体类型作为一个整体能否被外界访问;二是,如果该结构体可以被访问,那么哪些字段可以被外界访问?哪些字段不能被访问?
总体的情况是,结构体及其字段、关系函数和方法的可见性,大致可分为两个级别。一个是公共的(用pub关键字标),另一个是私有(默认)的。对于公开级别的,如果定义该结构体所处的模块能被使用者所在模块可见,那么对应被标记的结构体或字段也能被使用者访问,否则不可访问。对于私有级别,仅能在定义该结构体的当前模块内被访问。
先看一例子吧。
// main.rs
struct Horse {
name: String,
age: u8,
gender: u8,
skin_color: String,
}
impl Horse {
fn new(name: String, age: u8, gender: u8, skin_color: String) -> Self {
Horse {
name,age,gender,skin_color,
}
}
fn run(self) {}
fn carry(&self,goods: u16) {}
}
fn main() {
let horse = Horse::new("丰行".to_string(),
28,
1,
"白色".to_string());
let name = horse.name.clone();
horse.carry(100);
}
以上代码可以正常通过编译,在main函数中可以访问Horse类型及其关联函数与方法。这是因为,mian函数与结构体的定义在同一个main.rs文件中,虽然结构体以及内部的字段和关联函数与方法都是私有的(没有加上pub关键字)。
再举一个例子。
/// horse.rs
struct Horse {
name: String,
age: u8,
gender: u8,
skin_color: String,
}
impl Horse {
fn new(name: String, age: u8, gender: u8, skin_color: String) -> Self {
Horse {
name,age,gender,skin_color,
}
}
fn run(self) {}
fn carry(&self,goods: u16) {}
}
/// main.rs
mod horse;
use horse::*; // 先忽略此行
fn main() {
let horse = Horse::new("丰行".to_string(),
28,
1,
"白色".to_string());
let name = horse.name.clone();
horse.carry(100);
}
这一次,我们把定义马的逻辑抽到了horse.rs中,并通过mod horse导入至main中作用域中。编译上面的代码,会出现类似:failed to resolve: use of undeclared type Horse的错误信息,表明不能识别Horse类型,也就是说Horse类型不能被外界访问。因为,我们的Horse默认的可见性是私有的,其仅能在hosre模块内被访问。要想让上面的main函数通过编译,必须修改代码。修改后可可编译的代码如下:
/// horse.rs
pub struct Horse { //加上pub,以便外界可访问
pub name: String, //加上pub,以便外界可访问
age: u8,
gender: u8,
skin_color: String,
}
impl Horse {
pub fn new(name: String, age: u8, gender: u8, skin_color: String) -> Self {
Horse {
name,age,gender,skin_color,
}
}
fn run(self) {}
//加上pub,以便外界可访问
pub fn carry(&self,goods: u16) {}
}
可见,想对外公开,只需在前面加上pub 关键字。好了,这就是有关结构体中可见性的情况了。
让我们来作个简单的总结:
pub关键字。如果结构体本身是私有的,其字段与关联方法必然也是不可访问的。pub关键字。pub关键字。所谓的内存布局,是指结构实例中的字段在内存中是如何被排列的,以及该实例最终所占用的内存空间尺寸。这里涉及到一个重要的话题,就是内存对齐问题。至于什么是内存对齐,以及为什么需要内存对齐,我不想做过多的讨论,要彻底地讲清楚可能需要开一篇专文。在这里打一个不是很恰当也不准确的比方,但可以方便我们理解。把数据比做是物品,把内存比做是一个连续的场地,场地上画了一条线性排列的格子,每一个格子都标有序号用以表示它的位置,物品整齐地摆放在场地的格子里。把 CPU 比做人,人与这些物品打交道时,人需要走到这些格子上去查看或者拿取物品。假设人走路时每走一步可以跨越 N 个格子,那么如果一个数据从其开始到结束点的长度,处在两个步伐的交叉处,就很不方便,自然会影响工作效率。最理想的情况是,这些数据尽量都放在步行的起始处(或步长内)。
Rust 内存布局问题的关键,是内存对齐。内存对齐问题,分基本数据类型与自定义类型两种情况,现在我们分别来讨论。
比如 u32 需要在内存中以 4 字节对齐,u8 类型则需要 1 字节对齐。通常一个占用 N 个字节的类型,它的实例就是按 N 个字节对齐。按 N 个字节对齐的意思是,存放它的地址必须是对齐值N的整数倍,当 N 为 1 时,表示可以存储在任意位置。
结构体作为一个独立的数据类型,它的对齐值取决于其所包含的字段类型。会以所包含字段中类型长度最大的值,作为整个结构体的对齐值。然后再按照这个对齐值,对字段进行排列组合,再进行填充(padding)。结构体最后所占用的内存长度,等于各字段原本的数据长度,再加上,所有字段的 padding 长度的总和。
看一个实际的例子:
#[derive(Debug)]
struct Example {
a: u8, // 1 字节
b: u32, // 4 字节
c: u16, // 2 字节
}
fn main() {
let ex = Example {a:1,b:2,c:3};
println!("Example size: {}", std::mem::size_of::<Example>()); // 输出大小
println!("Align of struct: {}", std::mem::align_of::<Example>()); // 输出对齐值
}
运行上面程序,会输出:
Example size: 8
Align of struct: 4
表明结构体Example实例在内存占用 8 个字节,整个结构体的对齐值为 4 个字节。实例ex在内存中的具体布局如下图所示:
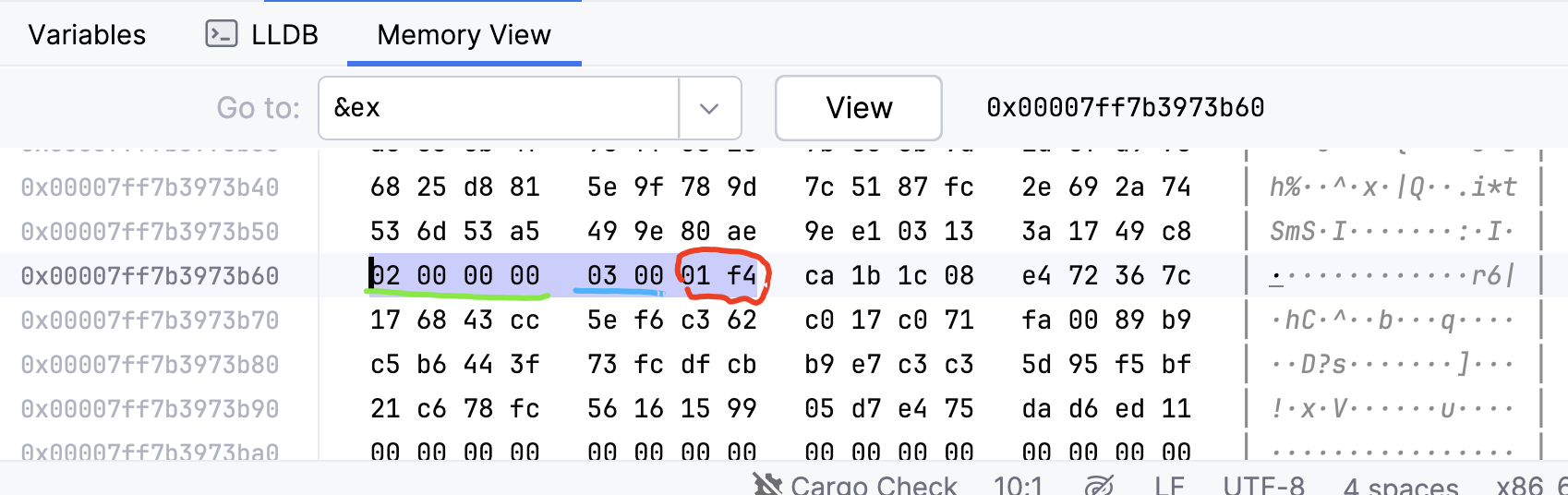
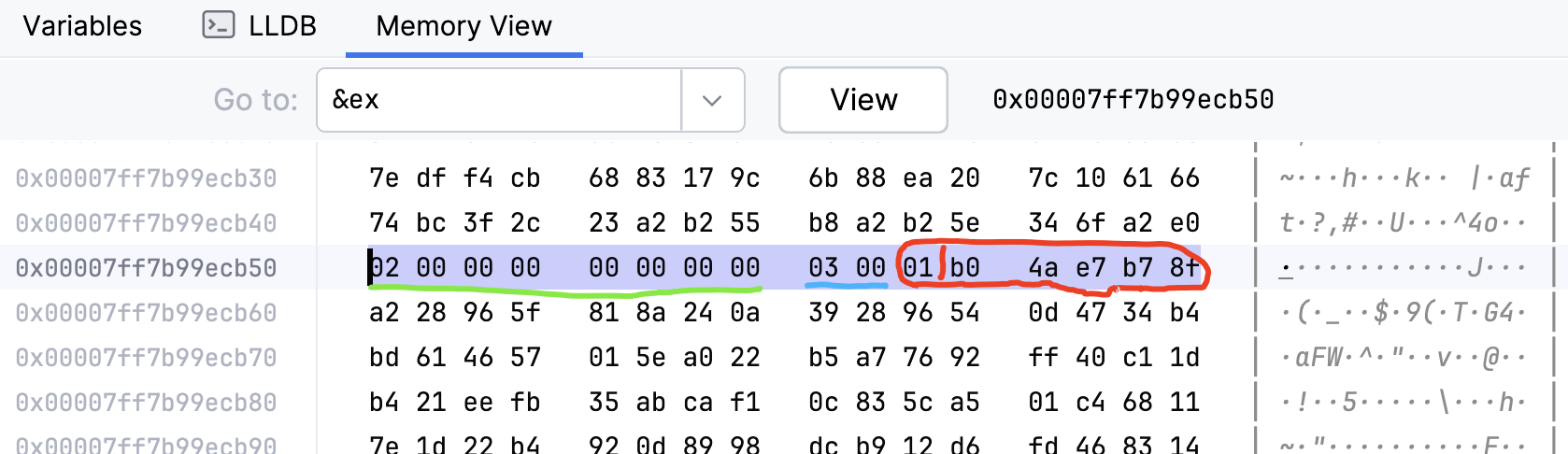
如果我们把b:u32 改为b: u64,程序会输出:
Example size: 16
Align of struct: 8
此时,内存布局如下:
通过这个例子,我们可以得到正常情况下,Rust 中结构体实例在内存布局的规律:
如果一个结构体的对齐值是 N ,那么结构体的总长度必须是 N 的整数倍。
为了匹配对齐值,编译器会根据情况把多个字段合并在一起,并插入0作为 padding。如果是最后一个字段,不会插入填充值,比如上图中的字段a:1,其后面的b04ae7b78f 是内存中原本的内容。这是可以理解的,因为当访问ex.a的时候,已经找它的起始地址,再选择一个字节的长度(u8的宽度)即可,后面的信息自然可以忽略掉。
Rust 为我们提供另外几种内存布局模式,用于某些特定的场景。
#[repr(align(N))]#[repr(align(N))] 允许我们显式地为结构体或类型指定一个对齐值,这对于优化内存布局或者确保特定的对齐需求非常有用。该属性将确保该类型的对齐值为N个字节。
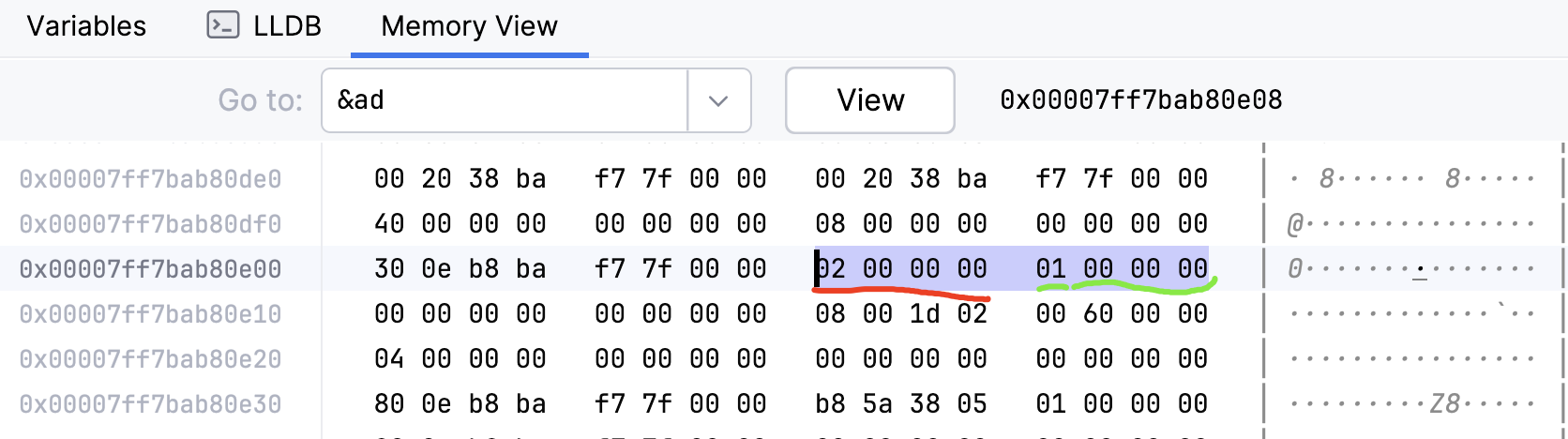
假设我们想要确保结构体按照 8 字节对齐:
#[repr(align(8))]
struct AlignedStruct {
a: u8,
b: u32,
}
fn main() {
println!("Size of AlignedStruct: {}", mem::size_of::<AlignedStruct>());
println!("Align of AlignedStruct: {}", mem::align_of::<AlignedStruct>());
}
输出:
Size of AlignedStruct: 8
Align of AlignedStruct: 8
该类型实例的内存布局如下图:
#[repr(C)]#[repr(C)]可以确保 Rust 结构体的内存布局与 C 语言的结构体布局一致。这对于与 C 语言进行 FFI(外部函数接口)时非常重要。C 语言的结构体通常要求严格的内存布局,因此 Rust 必须遵循与 C 相同的规则。
#[repr(C)]
struct Example {
a: u8,
b: u32,
}
FFI 是一个很重要的内容,现在你只需要知道是用来和 C 交互的就行了。C 中结构体布局问题请查阅其相关的内容。
#### #[repr(transparent)]
#[repr(transparent)]是 Rust 中用于新类型模式的一种标记,它用于指示一个结构体或枚举具有透明的内存布局,也就是说,结构体的内存布局与其唯一字段的内存布局完全相同。该标记常用于封装底层类型时,避免对齐和大小的改变,从而保持与底层类型相同的内存布局。
#[repr(transparent)]
struct MyU32(u32);
fn main() {
println!("Size of MyU32: {}", std::mem::size_of::<MyU32>());
println!("Align of MyU32: {}", std::mem::align_of::<MyU32>());
}
输出:
Size of MyU32: 4
Align of MyU32: 4
这会使得结构体 MyU32 的内存布局与其唯一字段 u32 完全相同,且不会引入任何额外的填充字节或对齐要求的改变。这样做的好处是,便于与 C 语言等其他语言进行互操作。如果我们希望在 Rust 中封装一个 C 语言中的类型,并确保其内存布局与 C 类型兼容,#[repr(transparent)] 是一个理想的选择。
#### #[repr(packed)]
#[repr(packed)] 属性可以让 Rust 编译器取消结构体中的填充字节,使得结构体紧凑地排列。这种方式可能会导致字段不符合其自然对齐要求,因此在访问这些字段时需要特别小心,以避免性能问题和潜在的未定义行为。
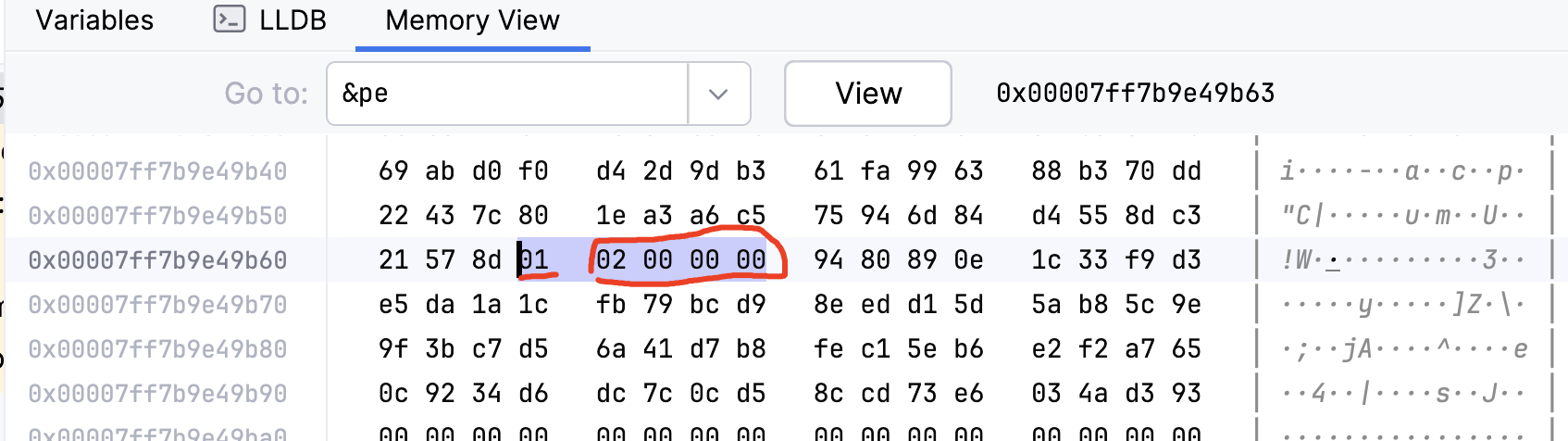
#[repr(packed)]
struct PackedExample {
a: u8,
b: u32,
}
PackedExample的对齐值为:1,其实例的总长度为:5。对应的内存布局如下:
本文系统地讨论了结构体相关的内容,主要包括结构体的意义、结构体的定义与实例化以及关联函数与方法等内容。在文章后面,还就结构体的可见性与内存布局等问题,进行了简要地介绍。结构体是构建 Rust 程序的重要构件,希望本文能对正在学习 Rust 的您有好所帮助。
好了,这可能是结构体中的所有内容了!嗯,我是说可能是。