Rust 是一种强类型语言,意味着每一种“东西”都应归属于某一种确切的类型。类型信息为如何解读内存数据提供了一种标准,明确地规定了其所占内存的宽度与所能表达的范围。在 Rust 中,除指针类型(引用、Trait Object等)外,其类型的取值范围都是一个有限集合,理论上都是可以被枚举的。比如,u8 的取值范围是[0,255]。
但 Rust 为什么还要专门设计一个枚举(Enum)出来呢?其想重点表达的意思是:这种类型其的取值范围相对很少,少到只需要扳扳指头就可以把它枚举完。比如,年循四季,月藏三旬,周迭七日,日替昼夜,人分男女。
通过枚举机制,用户可以根据业务需求,精确地设计其类型的取值区间。这样做的好处是,能充分享受 Rust 强大的类型系统的红利,把因类型歧义所导致的相关潜在问题提前暴露到编译时。
Rust 中的枚举,分为两种。一种跟 C 语言差不多,可以刻画一个枚举所包含的各种状态;另一种,不只可以表示不同的状态,还可以给状态关联上数据。为了方便讨论,我们姑且把前者称为常规型枚举,后者为关联型枚举。
要在 Rust 中定义一个枚举类型,只需要用enum关键字,后面跟着你想要定义类型的名称,然后用对花括号开启一个代码区。在代码区中,分别标记出想要的被称作为变体的状态即可。
//枚举的名称,通常遵循驼峰式命名、大写字母开头
enum EnumName {
State1, //变体1
State2, //变体2
State3, //变体3
...
}
作为与结构体中字段的区别,枚举中的状态被称作为变体。它强调的是,各个状态之间的关系是排它的。即一个具体的枚举实例的值在这些状态中变化,在某一时刻只能是其中某一种状态。
来看一个例子,如果要定义表示性别的枚举 Gender,它的可能取值范围是:雄性 与 雌性。
/// 表示性别的枚举
enum Gender {
Male, // 雄性
Female, // 雌性
}
现在已经定义好了 Gender枚举类型,可以创建该类型的两个不同变体的实例:
let male = Gender::Male;
let female = Gender::Female;
注意上面的::连接符号,它表示是某个枚举类型下面的某个的变体。我们采用EnumeName::StateName方式,唯一确定一个枚举值。这与老式的 C 语言中的枚值是不一样的。其好处是,不容易出现名称上的冲突,同一个变体的名字可以在别的枚举中使用。
由于Gender::Male 和 Gender::Female都是 Gender类型的值,那么就可以把它们传递到一个接收Gender类型作为参数的函数中了。比如:
fn perform_some_task_with_gender(gender: Gender, ...some_rest_args) {}
还记得我们之前为老刘的马定义的结构体吗?当时,我们把马的性别定义为u8,并约定:0表示母马、1表示公马。那么实例化时,如果传入数字100,该如何应对呢?在根据性别作不同处理的代码逻辑中,就可能会出现业务层面的Bug!如果使用我们定义的Gender作为类型的话,就不会出现上述的问题,因为其取值被限制了在合法的范围内。下面是修改后的代码:
struct Horse {
// --snip--
gender: Gender, // 马的性别,被限制在合法的范围内。
// --snip--
}
与传统的 C 语言不同,Rust 支持在枚举中的变体上关联想要的数据。其大致语法如下:
enum EnumName {
State1,
State2(AssociatedType1),
State3(AssociatedType2),
...
}
对所关联的数据类型没有要求,可以是除正在定义的枚举本身类型之外的任何类型。如果想关联正在定义的枚举本身类型,可以改为相应的指针类型。另外,在一个枚举类型中,没有关联数据的变体 可以与关联数据的变体并存。各个变体所关联的数据类型也可以不一样。
我们乘坐时间快车,穿越至大明洪武年间,来到了去圣人山冬瓜岭的路上。刚越岭,见一人立于松下,时远眺东南之来路。见我等来人,笑迎而至。拱手道:“昨夜梦中见天开,知有贵客至,今早候于此矣。”此人正是故人一明先生。入其舍,鸡鸣犬吠,堂中新筑土屋,梁柱粗实,院中竹篱环绕,鸡鸭成群,颇具田园之乐。一明端茶以待,笑言:“吾弃文而耕田,六载有余,方知躬耕自乐,胜于枯坐书斋也。”茶过三盏,杀鸡烹羊,炖汤煮菜。红泥火炉笑欢颜,几碗浊酒话天边。与君共此时,一杯何以酣?
看得出来,一明先生通过几年辛勤劳作,积累了不少的财富。下面是老刘脱密后的资产清单:
妻:只能有一个,这是明朝哦,女人也是男人的财产
妾:可以有多个
房屋:以栋数为单位计数
家畜:牛、马、羊等
粮食:玉米、稻谷、黄豆等
蔬菜:因白菜等无法保存,通常直接长在地里,以种植面积计算
为了记录老刘手头的资产,我们怎样设计相关的数据类型呢?一个常见的思路,先设计一个用来表示资产种类的枚举,再设计一个包含有 2 个字段的结构体,一个字段的类型为资产种类,别一个为对应的数量。但是,这里存在一些棘手的问题,有的种类不需要数量信息(因为它只有一个,比如妻子),有的种类又存在多级嵌套(比如牛和玉米,它们还存在上一级类型)。当考虑到这些问题之后,其复杂性就增加了不少。面对这种场景,正是 Rust 中枚举发挥威力的时候,因为它可以关联数据。现在,我们尝试设计一下吧。
/// 资产枚举
enum Asset {
Wife, // 正妻,只能有一个,故无需关联数据
Concubine(u8), // 妾,可以有多个
House(u8), // 房子,以栋计算
Livestock(LivestockType), // 家畜,关联家畜种类
Grain(String, u32), // 粮食作物,关联作物种类和存量(单位:斤)
// 因为蔬菜不便储存,所以以种植面积估算
Vegetable { // 蔬菜,使用结构体样式,关联蔬菜种类和种植面积
name: String, // 蔬菜名称,假设种类繁多不便统一,使用String
area: f32, // 种植面积(单位:亩)
},
}
/// 家畜种类的枚举
enum LivestockType {
Cattle, // 牛
Horse, // 马
Goat, // 山羊
Pig, // 猪
Dog, // 狗
}
对于Asset枚举,其中的Wife没有关联数据,Concubine和House关联的是一个单一类型u8,Livestock关联的是另一个枚举类型LivestockType,Grain关联的是元组类型(String, u32)。Vegetable比较特殊,它关联的是一种称作为匿名结构体的类型:{name: String, area: f32,}。
定义好了这些类型后,就可以用它们来表示具体的资产呢了。
// 300斤稻谷
let paddy = Asset::Grain("稻谷".to_string(), 300);
// 1.5亩白菜
let cabbages = Asset::Vegetable {name: "白菜".to_string(),area: 1.5,};
// 牛
let cattle = Asset::Livestock(LivestockType::Cattle);
细心的同学应该已经发现,上面的类型设计是有缺陷的,不是吗?现在只能标识家畜种类,不能记录其数量。所以,我们要对上面的LivestockType做一些调整,其目的是用于资产的统计,所以需要另外再设计一个类型。下面是重新设计后的代码:
/// 用于资产统计的家畜种类的枚举
enum LivestockAssetType {
Cattle(Gender, u8), // 牛
Horse(Gender, u8), // 马
Goat(Gender, u16), // 山羊
Pig(u8), // 猪 作为资产,在市面上不需要区分公母
Dog(u8), // 狗 作为资产,在市面上不需要区分公母
}
/// 资产枚举
enum Asset {
// --snip--
Livestock(LivestockAssetType), // 家畜,关联家畜种类
// --snip--
}
现在,我们就可以记录家畜资产了:
// 3头公牛
let cattle_asset = Asset::Livestock(LivestockAssetType::Cattle(Male, 3));
// 2匹公马
let horse_asset = Asset::Livestock(LivestockAssetType::Horse(Male, 2));
完美!是不是很方便呢?
枚举还有一个好处就是,通过把不同的类型包装在同一个枚举类型中,使其成为同一的类型,方便与外界交互。比如下面的记账函数,它根据家畜市场价格,把各种资产货币化后记入相应的会计科目中。虽然资产种类繁多,但由于我们通过枚举把它们统一化了,所以不管是牛还是马,都可以被视作同一物传入到函数的参数中。
fn record_assets2accounts(livestock: LivestockAssetType){...}
枚举跟结构体一样,也可以有关联函数与关联方法。其使用要求与结构体是一样的,具体情况请参照结构体中相关内容,在此就不再赘述了。
Option 是 Rust 标准库中一种枚举,它用来表明一个类型可以有空值的概念,即要么有效值,要么为空。其设计目的是为了解决传统编程语言中空值(null)引发的问题,通过类型系统提供一种安全、显式的方式来表示一个值要么存在(Some),要么缺失(None)。在许多语言中,空值通常由 null 或类似的概念表示,这种设计虽然简单,但存在一些显著问题:首先,空值的存在是隐式的,程序员无法在类型层面确定某个值是否可能为 null;其次,访问空值通常会导致运行时错误,这种错误往往不容易在编译阶段发现。
Option 的定义如下:
enum Option<T> {
Some(T), // 表示值存在,包含一个类型T的值
None, // 表示空值
}
Some(T)表示有一个类型T 的值,T是一个泛型类型(我们还没有学习泛型,你现在可以简单地把它当成是一个类型的占位符),这意味着 Option 枚举的Some变体可以包含任意类型的数据。None表示没有值,等同于别的语言中空值(null)的概念。看几个例子:
let some_number = Some(5); // some_number的类型为 Option<i32>
let some_string = Some("a string"); //some_string的类型为 Option<&str>
let absent_number: Option<i32> = None; //必须加上完整的类型信息,因为无法推定Option<T>中的T
如果使用 None 而不是 Some,需要告诉 Rust Option<T> 是什么类型的,因为编译器只通过 None 值无法推断出 Some 成员保存的值的类型。每一个Option<T>中,都可能会有None,无法分辨它到底属于哪一个类型。
当为Some值时,我们就知道存在一个值。当为None值时,在某种意义上,它跟空值具有相同的意义:并没有一个有效的值。那么,Option<T>为什么就比空值要好呢?因为Option<T> 和 T是不同的类型,编译器不允许像一个肯定有效的值那样使用Option<T>。例如,这段代码不能编译,因为它尝试将Option<i8> 与i8 相加:
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
我们忽略编译器的具体错误信息,尝试分析一下它未能通过编译的原因。给一个变量指定为Option的时候,我们是想表达它可能不存在值(空值),那么在使用的时候,我们肯定需要注意它的非空与空的两种状态,对其分别做出相应的处理,特别是当它是空的情况。也就是说,Rust 通过提供Option<T>类型,让它与T是两个不同类型,这样会由类型系统保证程序员不会忽略对空值存在。如果采用传统语言中的空值(null机制,由于空值隐含在类型中(一体两面),一不小心就会忽略对空值的特殊处理。
类型系统阻止Option<i8> 与i8相加,因为它们不是同一种类型,或者说两个类型之间没有实现相加法操作。只有在Option<i8>存在有效值的时候,把有效值i8抽取出来后才能相加。代码如下:
let x: i8 = 5;
let y: Option<i8> = Some(5);
//如果是Some(T),获取内容T;如果是None直接panic
let y_i8 = y.unwrap();
let sum = x + y_i8;
从Option中获取有效值,可以通过代码所示的unwrap(如果能确定它有值),也可以采取后文介绍的match与if let。
Option是一个非常强大的工具,标准库和实际项目中都有它的身影。它提供了大量实用的API,我们不可能介绍它的所有细节。其具体情况,请参照相关文档。
Result是标准库给我提供的另一个很重要的枚举类型,其主要作用是用于错误处理。关于错误处理的内容,后续会有专文介绍。在这里,只是从枚举类型的角度,对它作一个简单的介绍。其定义如下:
enum Result<T, E> {
Ok(T), // 表示操作成功,包含成功的值 T
Err(E), // 表示操作失败,包含错误信息 E
}
Result是一个枚举,包含两个变体:Ok(T) 和 Err(E)。Ok 表示操作成功,并包含成功的值 T;Err 表示操作失败,并携带错误信息 E。这种双重状态的设计,使得程序员在使用时必须显式地处理错误情况,从根本上避免了传统异常机制可能带来的隐蔽性问题。
match 是一种控制流运算符,在功能上类似于if else 和有些语言(比如 C 语言)中的swith语句。但match要比它们强大,因为它在做判断时支持模式匹配(模式匹配会另开专文讨论)。可以把模式匹配想象成某种硬币分类器:硬币滑入有着不同大小孔洞的轨道,每一个硬币都会掉入符合它大小的孔洞。同样地,值也会通过 match 的每一个模式,并且在遇到第一个“符合”的模式时,值会进入相关联的代码块并在执行中被使用。
还是拿我们之前提及过的家畜记帐函数为例,看看如何使用 match 实现其记帐逻辑。
fn record_assets2accounts(livestock: LivestockAssetType) {
// --snip--
match livestock {
LivestockAssetType::Cattle(gender, count) => { /*在花括号内,处理牛相关的逻辑*/ },
LivestockAssetType::Horse(gender, count) =>
Horse::record_2_accounts(gender, count),//一条语句不用加花括号
LivestockAssetType::Goat(_, count) => {/*在花括号内,处理羊相关的逻辑*/},
LivestockAssetType::Pig(cout) => {/*在花括号内,处理猪相关的逻辑*/},
_ => {/* _ 表示除了上面处理的状态外的其他所有状态,本例中只包括狗*/},
}
// --snip--
}
上面的示例代码,根据 livestock 的各种状态,分门别类地做了相应的处理。代码中各个状态关联的数据使用了模式匹配,比如:Pig(count),由于表示猪的变体定义是Pig(u8),所以count会匹配到猪所关联的数量;Cattle(gender, count),由于表示牛的变体定义是Cattle(Gender, u8),所以gender、count会分别匹配到牛所关联的性别与数量。还可以使用_,忽略相应的关联的数据,比如Goat(_, count)忽略羊的性别,这可能是公羊与母羊在市面上的价格是一样。
现在做一个简单的总结:
match会对一个值(表达式计算后会返回一个值),在所对应类型的所有取值范内进行判定,不能遗漏任何一种情形。=>后对应的代码段。判定时用到了模式匹配,它可以绑定值,以便在对应的处理代码中使用。也可以用-,忽略相应位置所对应的绑定的值。-表示除已经列出的状态之外的情况,这种情形也必须要有对应的处理。match 代码块在整体上作为一个表达式会返回值,这就意味着各个分支处理代码(=> {...})返回值的类型必须一致。关于上述的最后一点,举个例子解释一下。比如:
fn handle_with_gender(gender: Gender) {
// --snip--
match gender {
Male => {println!("malle");}, //此处的返回类型是 `()`
Female => 3, // 此处的返回类型是 `i32`
}
// --snip--
}
编译上面代码会出现:match arms have incompatible types的错误,这是显然的,因为match 作为一个表达式,它应该有自己确切的类型,而出现两种不一样的类型必然是不允许的。如果还不明白,把它赋给一个变量就明白了。
// 当编译器为`ret`推定类型时,就陷入了两难之地。ret到底应该是哪种类型呢?
let ret = match gender {...};
在搞明白了match后,再来讨论if let就相当简单了。我们知道,使用match时,必须要对每一种情况都进行处理,漏掉任何一个都不能通过编译。试想这样一个情况,假如一个枚举有 10 个状态,我们只关心其中的某一个状态,其他情况全部忽略。如果用match实现的话,代码逻辑大致如下:
match some_enum_instance {
Sate_Cared => {...},
_ => {...}
}
这样是不是很麻烦?每一次都必须写上_来处理其他情况。在这种场景下,就是if let发挥威力的时候,可以少写很多代码。与上面样版代码等价的用if let代码如下:
if let some_cared_enum_value = some_enum_instance {
...
};
下面我们分别用match与if let举几个具体例子,两者都完成一样的功能。
let livestock_asset = LivestockAssetType::Dog(3);
match livestock_asset {
LivestockAssetType::Dog(n) => println!("There have {} dogs", n),
_ => (),
}
//对应的`if let`代码:
if let LivestockAssetType::Dog(n) = livestock_asset {
println!("There have {} dogs", n);
}
if let 还可以跟上else,用于处理其他的情形,比如:
let mut count = 0;
let some_u8_value = Some(0u8);
match some_u8_value {
Some(3) => count += 1,
_ => count += 2,
}
//对应的`if let`代码:
if let Some(3) = some_u8_value {
count += 1;
} else {
count += 2;
}
在 Rust 中,枚举的内存布局由两部分组成:
枚举的内存分配方式取决于其变体及其关联数据的特性。Rust 会采用一种最优的方式,以确保枚举占用最小的内存空间。
对于不携带关联数据的枚举(称为 C 风格枚举),其内存布局与整数非常相似。例如:
enum Direction {
North,
East,
South,
West,
}
Direction 枚举包含四个变体,每个变体的值在底层会被编译为整数。具体的布局可以类比为:
| 枚举变体 | 对应整数值 |
|---|---|
North |
0 |
East |
1 |
South |
2 |
West |
3 |
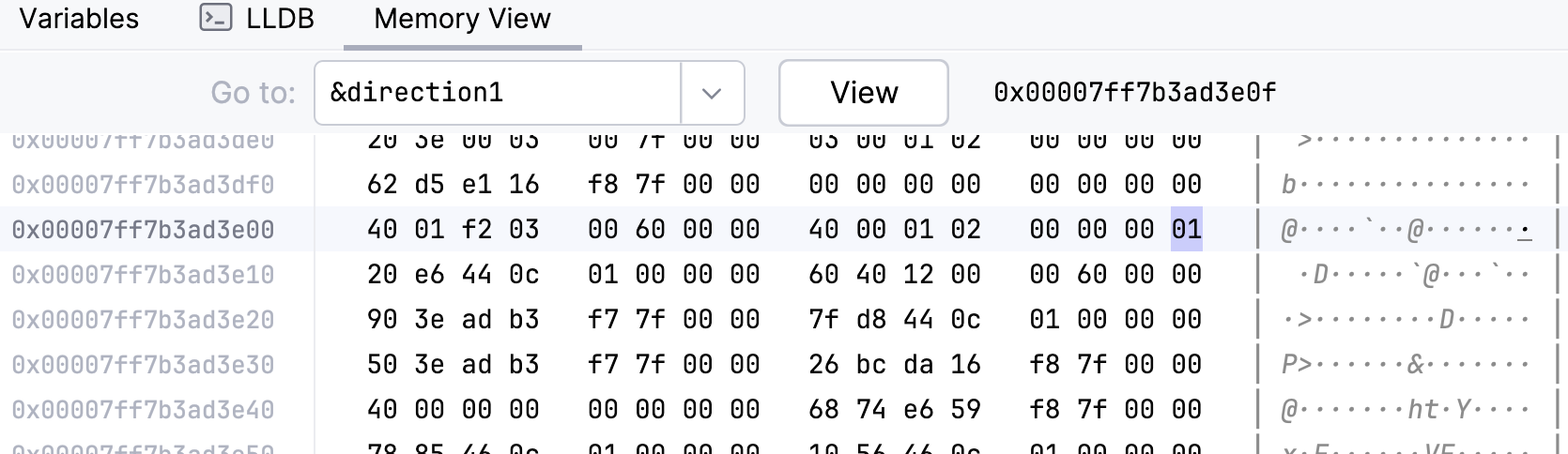
此时,Direction 的大小为一个 u8,因为取二位就足够了(2 的 2 次方刚好能表示四个变体),但长度是以字节为单位,最少也要一个字节 (u8)。
fn main() {
let direction1 = Direction::East;
println!("Size of Direction: {}", std::mem::size_of_val(&direction1)); // 输出 1
}
所对应的内存布局如下图:
如果枚举的变体携带数据,Rust 会为变体关联数据分配内存,并在枚举中增加一个标签来指示当前变体。例如:
enum Value {
Int(i32),
Float(f64),
}
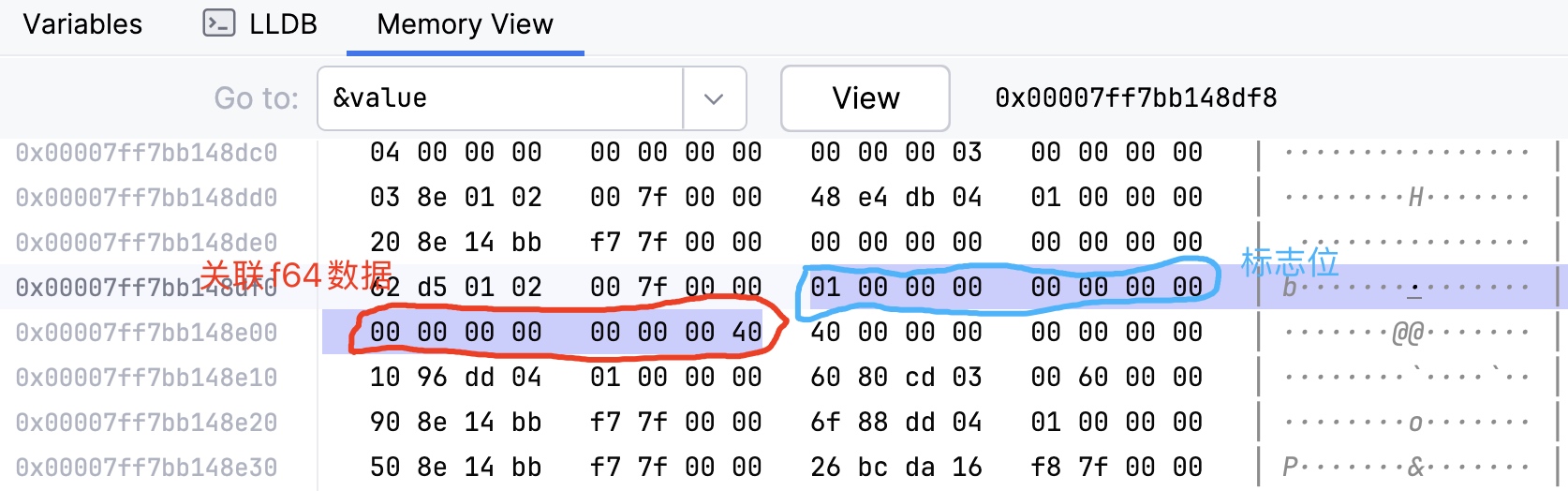
在这个例子中,Value 的内存布局需要同时容纳:
Int 或 Float)。f64 占 8 字节)。因此,Value 的内存大小为 16 字节。这是因为:最大的变体是f64类型,需要占用 8 个字节,另外还有用于记录变体的标签位占 1 个字节。这两者跟结构体字段一样是组合关系,所以需要参照结构体布局方案,即需要考虑内存对齐。对齐值为两者的最小公倍数,所以对 1 个字节的标签位扩展到 8 个字节。
fn main() {
let value = Value::Float(2.0_f64);
println!("Size of Direction: {}", std::mem::size_of_val(&value)); // 会输出 16
}
所对应的内存布局如下图:
Rust 利用指针的特殊值(如 NULL)优化内存布局,使一些枚举类型不需要额外的空间。例如:
enum Option<T> {
Some(T),
None,
}
对于 Option<&T> 类型,Rust 会利用指针值本身的空值语义进行优化:
因此,Option<&T> 与 &T 的大小是相同的,不需要额外的内存。
use std::mem;
fn main() {
let v = 42;
let some_value: Option<&i32> = Some(&v);
let none_value: Option<&i32> = None;
println!("Size of Option<&i32>: {}", mem::size_of::<Option<&i32>>()); // 输出 8,即一个指针(地址)的长度
}
some_value 与 none_value 所对应的内存布局图:
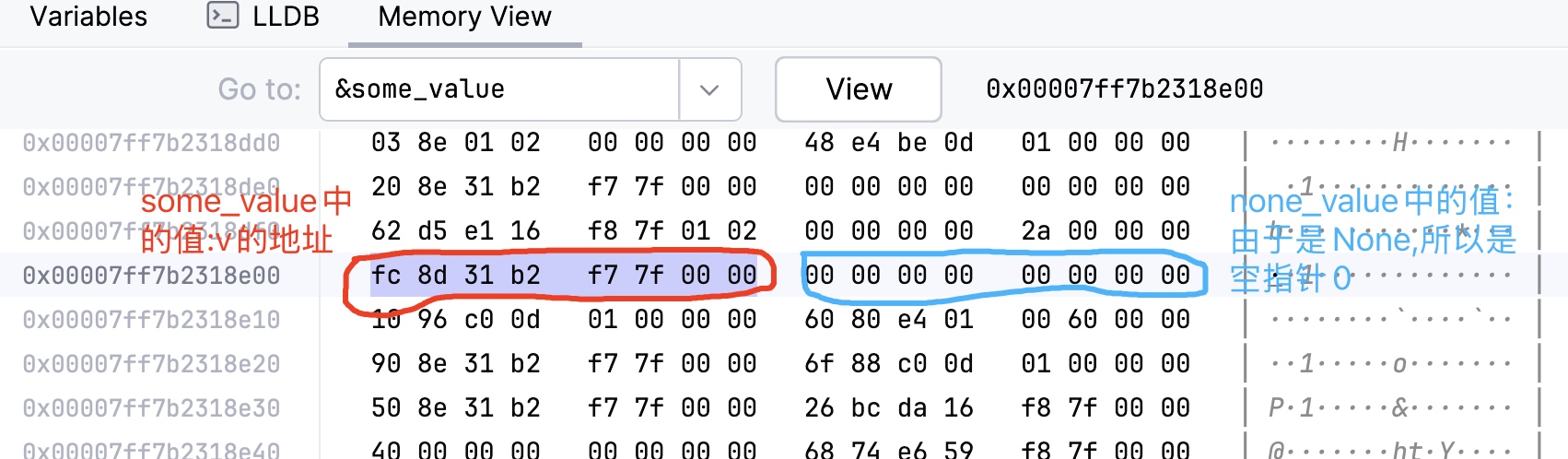
可见,对于 Option<&T> 类型,即使包含两种状态,其大小与普通指针一致。
对于枚举的布局问题,我们简单总结如下:
本文系统地讨论了枚举相关的话题,主要包括枚举的意义、枚举的定义与实例化、Option和Result等内容。在文章后部分,还就如何使用match、if let控制流运算符操作枚举、枚举的内存布局等内容,进行了简要地介绍。枚举与结构体一样,都是构建 Rust 程序的重要构件,希望本文能对正在学习 Rust 的您有好所帮助。